FRAMEWORK AND OBJECTIVES OF RESEARCH
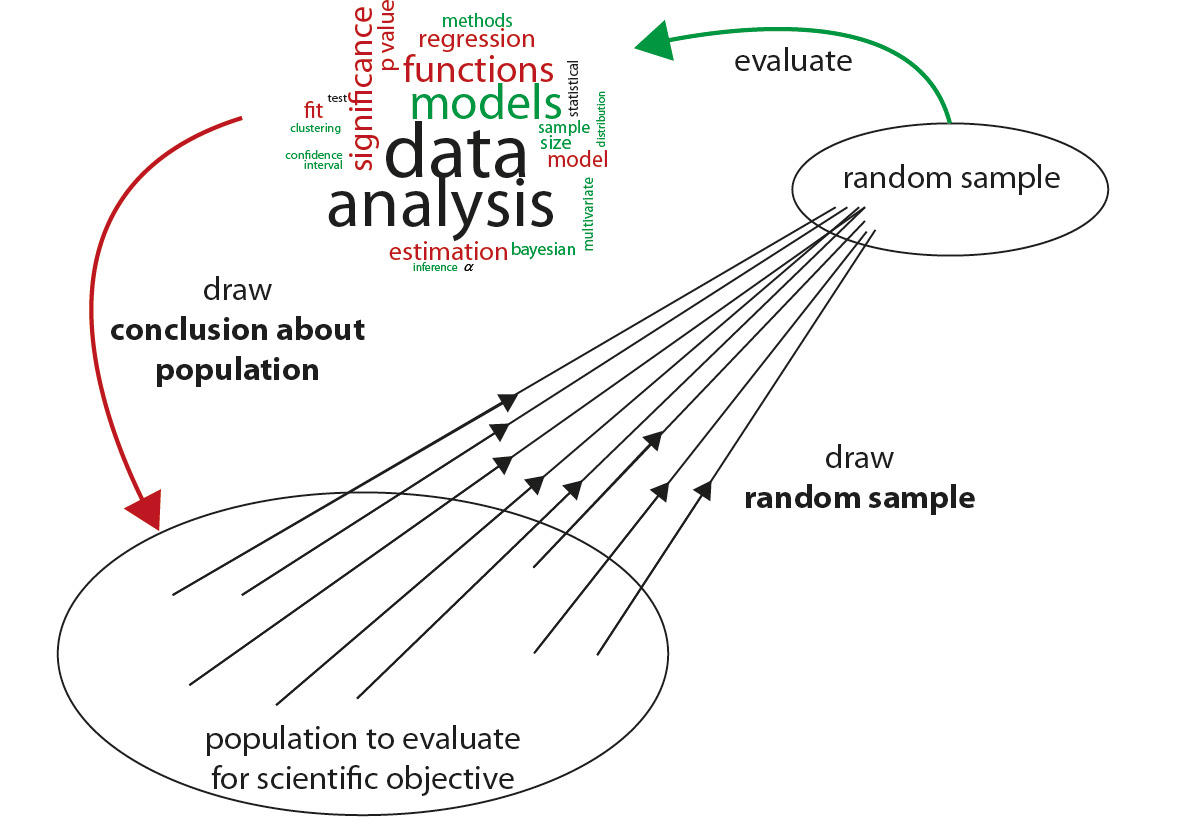
In this lesson we saw the concept of theoretical framework,
which seeks to define where we want to go with the research we want to achieve.
To build a theoretical framework requires four steps:
*Formulate precisely a question of the patient or of the
unit.
*Locate the evidence available in the literature.
*Critical evaluation of the scientific literature or
evidence.
*Implementation of the conclusions of this evaluation
practice.
This topic also saw the concept of hypothesis, which
is merely a statement of the expectations of the research, about relationships
between variables that are queried.
It is therefore a prediction of the results expected
to get between two or more variables.
Where we have independent variables (which are those that
explain) and a dependent variable (from which we get the result)
For example, in a study to associate the number of blood
pressure and the incidence of stroke.
Independent variable: Blood Pressure.
Dependent variable incidence of stroke.
When there is no relationship between the variables, called
null hypothesis.
When there is a difference between the two, we call
alternative hypotheses.
For example know whether snuff consumption influences the
occurrence of COPD.
Null hypothesis: there is no relationship between
consumption of snuff and COPD.
Alternative hypothesis 1: snuff increases the risk of COPD.
Alternative Hypothesis 2: snuff reduces the risk of COPD.
A few steps from being an expert in research!!